
AI 서비스를 만들 때 어떤 벡터 데이터베이스를 써야 할까? | 매거진에 참여하세요
AI 서비스를 만들 때 어떤 벡터 데이터베이스를 써야 할까?
#벡터DB #솔루션 #비교 #장점 #단점 #정의 #초기서비스 #클라우드서비스 #매니지드서비스




AI 서비스를 만들다 보면 어느 순간 거의 반드시 등장하는 기술이 하나 있다. 바로 Vector Database다.
특히 다음과 같은 기능을 만들 때는 거의 필수적으로 사용된다.
- RAG 기반 AI 검색
- 문서 기반 AI 챗봇
- 의미 기반 검색 (Semantic Search)
- 추천 시스템
문제는 Vector DB 종류가 생각보다 많다는 것이다.
조금만 찾아보면 이런 이름들이 등장한다.
Pinecone , Qdrant, Weaviate , Milvus , pgvector
처음 보면 자연스럽게 이런 질문이 생긴다.
“도대체 어떤 Vector DB를 써야 할까?”
이 글에서는 Vector DB가 왜 필요한지, 그리고 어떤 기준으로 선택하면 좋은지를 실제 개발 경험을 기준으로 정리해 보려고 한다.
Vector DB가 필요한 이유
먼저 Vector DB 이야기를 하기 전에 한 가지 질문을 해보자.
왜 굳이 Vector DB가 필요할까? 예를 들어 우리가 이런 기능을 만든다고 생각해 보자.
“사용자가 질문하면 회사 문서를 기반으로 답변하는 AI 챗봇”
이 기능을 구현하려면 먼저 문서를 AI가 이해할 수 있는 형태로 바꿔야 한다.
여기서 등장하는 개념이 Embedding이다.
Embedding은 텍스트를 숫자 벡터로 변환하는 과정이다.
예를 들어 이런 문장이 있다고 해보자.
“AI 스타트업 투자 시장”
이 문장을 embedding 모델에 넣으면 이런 형태의 벡터가 생성된다.
[0.21, -0.83, 0.12, 0.67, ...]
이 벡터는 문장의 의미를 숫자로 표현한 것이다.
흥미로운 점은 비슷한 의미의 문장은 비슷한 벡터를 가진다는 것이다.
예를 들어 이런 두 문장은 서로 가까운 벡터가 된다.
- AI 스타트업 투자 시장
- 인공지능 스타트업 투자 동향
이 특성을 활용하면 의미 기반 검색이 가능해진다.
그리고 바로 이 검색을 빠르게 수행하기 위해 사용하는 것이 Vector Database다.
Vector DB의 기본 구조
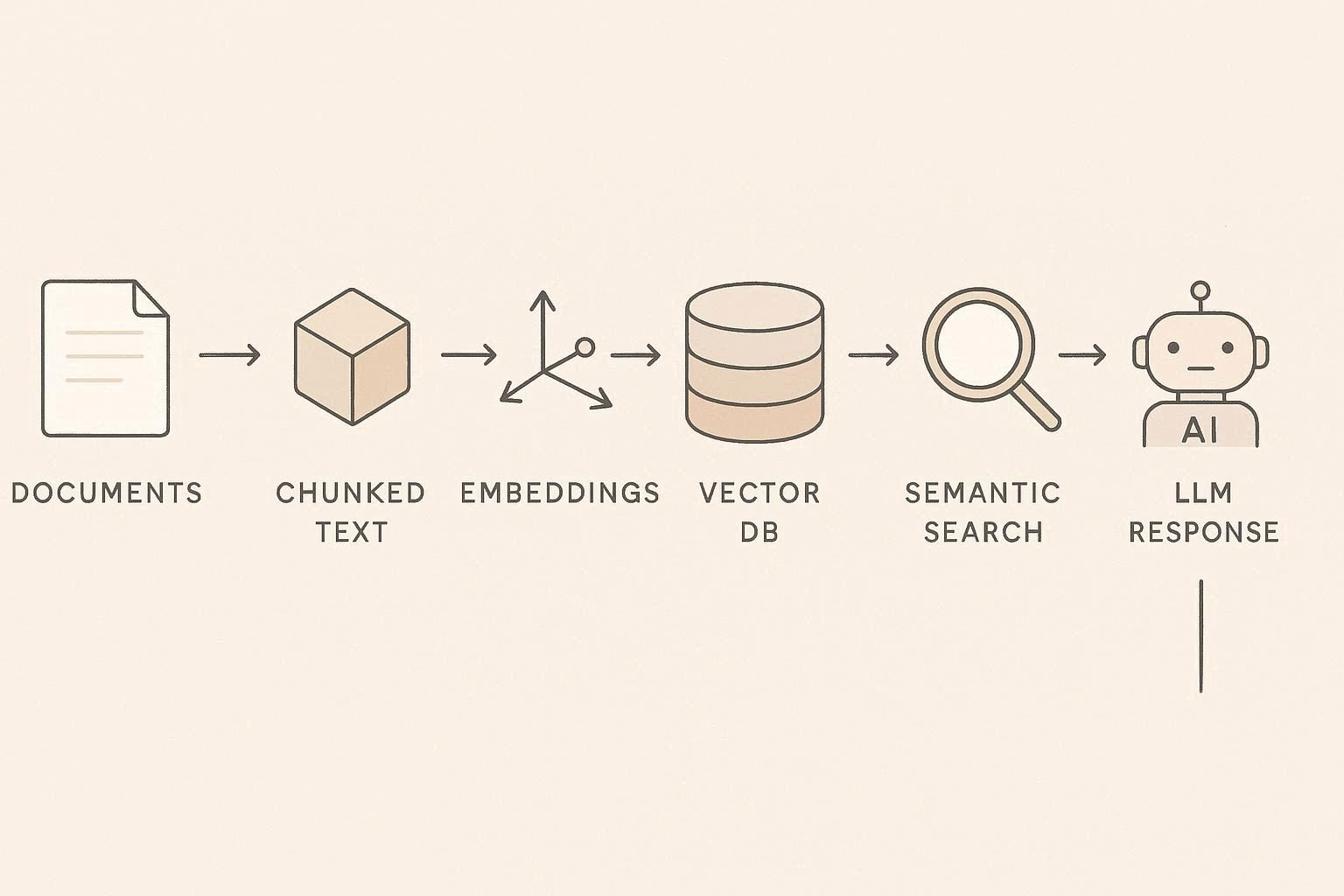
Vector DB 기반 검색은 보통 다음 흐름으로 동작한다.
먼저 문서를 여러 개의 조각으로 나눈다.
예를 들어 100개의 문서가 있다면 다음처럼 나눌 수 있다.
문서 → Chunk → Embedding , 각 chunk는 embedding 벡터로 변환된다 그리고 이 벡터들이 Vector DB에 저장된다.
사용자가 질문을 하면 다음 과정이 진행된다.
1. 질문을 embedding으로 변환
2. Vector DB에서 가장 유사한 벡터 검색
3. 관련 문서 chunk 반환
4. LLM이 해당 정보를 기반으로 답변 생성
이 구조를 보통 RAG (Retrieval Augmented Generation)라고 부른다.
즉 Vector DB는 AI가 필요한 정보를 찾도록 도와주는 검색 엔진 역할을 한다.
Vector DB 종류는 크게 세 가지
Vector DB를 선택할 때 가장 먼저 알아야 할 것은
Vector DB가 크게 세 가지 유형으로 나뉜다는 점이다.
이 구조를 이해하면 선택이 훨씬 쉬워진다.
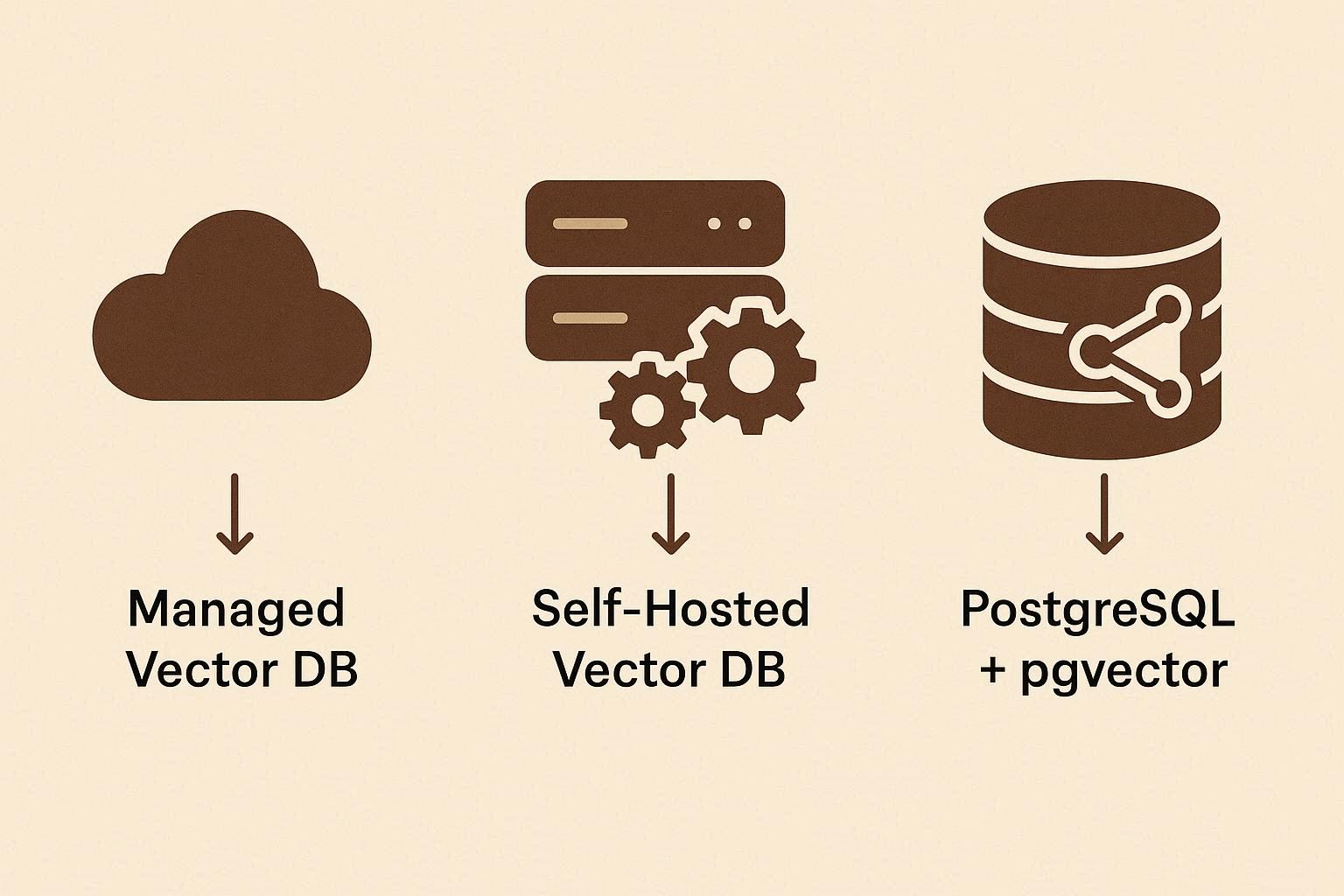
1. Managed Vector DB : 첫 번째는 완전 관리형 서비스다.
대표적인 서비스는 다음과 같다.
- Pinecone
- Weaviate Cloud
이 방식은 AWS RDS 같은 개념이라고 보면 된다.
서버를 직접 운영할 필요가 없다.
API로 벡터를 저장하고 검색하면 된다.
예를 들어 Pinecone을 사용하면 다음과 같은 코드로 벡터를 저장할 수 있다.
- vector upsert
- vector search
장점은 매우 명확하다.
- 빠르게 시작할 수 있다
- 서버 운영이 필요 없다
- 확장이 쉽다
하지만 단점도 있다. : 가장 큰 문제는 비용이다.
데이터가 많아지면 비용이 상당히 올라갈 수 있다.
그래서 많은 스타트업이 초기에는 Managed DB를 쓰다가 나중에 다른 구조로 옮기기도 한다.
2. Self-hosted Vector DB : 두 번째는 직접 서버에 설치해서 사용하는 Vector DB다.
대표적인 프로젝트는 다음과 같다.
- Qdrant
- Milvus
이 방식은 Docker로 쉽게 실행할 수 있다.
예를 들어 Qdrant는 다음처럼 실행할 수 있다.
docker run qdrant
장점은 다음과 같다.
- 비용이 훨씬 저렴하다
- 데이터 통제가 가능하다
- 성능 튜닝이 가능하다
특히 최근에는 Qdrant 같은 프로젝트가 상당히 성숙해졌다.
그래서 많은 AI 스타트업이 Qdrant를 기본 Vector DB로 선택하는 경우도 많다.
하지만 단점도 있다.
- 서버를 직접 운영해야 한다.
즉 다음과 같은 문제가 생길 수 있다.
장애 대응
스케일링
백업 관리
그래서 인프라 경험이 없는 팀에게는 부담이 될 수도 있다.
3. 기존 데이터베이스 확장 : 세 번째 방식은 조금 흥미롭다.
Vector DB를 따로 쓰지 않고 기존 데이터베이스에 vector 기능을 추가하는 방식이다.
대표적인 예가 바로 PostgreSQL + pgvector다.
pgvector는 PostgreSQL 확장이다.
즉 기존 Postgres에 vector 타입을 추가할 수 있다.
예를 들어 이런 구조가 가능하다.
table documents
id
text
embedding이 방식의 가장 큰 장점은 단순함이다.
이미 많은 서비스가 PostgreSQL을 사용한다.
그래서 새로운 DB를 도입하지 않아도 된다.
특히 다음 상황에서는 이 접근 방식이 매우 좋다.
- 초기 스타트업
- 작은 데이터 규모
- 빠른 프로토타입 개발
하지만 단점도 있다.
- Vector 검색 성능은 전용 Vector DB보다 떨어질 수 있다.
데이터가 수백만 개 이상으로 늘어나면 성능 문제가 발생할 가능성이 있다.
실제 프로젝트에서는 어떻게 선택할까?
실제 프로젝트에서는 보통 다음 기준으로 선택한다.
초기 프로젝트라면
PostgreSQL + pgvector 이 조합이 가장 간단하다.
이미 Postgres가 있다면 바로 시작할 수 있기 때문이다.
데이터 규모가 커지기 시작하면 Qdrant 또는 Milvus 같은 전용 Vector DB를 고려하게 된다.
그리고 인프라 관리가 부담스럽다면 Pinecone 같은 Managed 서비스 를 선택하기도 한다.
즉 정답은 하나가 아니다. 서비스의 규모와 팀의 인프라 역량에 따라 선택이 달라진다.
Vector DB 선택에서 가장 중요한 기준 네가지
1. 첫 번째는 데이터 규모다.
몇 천 개 문서라면 어떤 DB든 문제 없다.
하지만 수백만 벡터가 되면 상황이 달라진다.
2. 두 번째는 검색 속도다.
AI 서비스에서는 latency가 매우 중요하다.
Vector 검색이 느리면 전체 서비스도 느려진다.
3. 세 번째는 운영 복잡도다.
Self-hosted DB는 운영 부담이 있다.
팀의 인프라 경험을 고려해야 한다.
4. 네 번째는 비용이다.
Managed DB는 편하지만 비용이 올라갈 수 있다.
정리
Vector DB는 AI 서비스에서 점점 중요한 인프라가 되고 있다.
특히 RAG 기반 AI 시스템에서는 거의 필수적인 요소다.
초기 서비스 → PostgreSQL + pgvector
중간 규모 서비스 → Qdrant 또는 Milvus
빠른 개발과 관리 편의성 → Pinecone 같은 Managed DB
하지만 결국 가장 중요한 것은 서비스에 맞는 선택이다.
AI 시스템을 설계할 때는 Vector DB도 하나의 중요한 아키텍처 결정이 된다.

- link_kakaolink_kakao_url
- link_operatorlink_operator_url
- link_investhelp@letspl.me
- link_ad_urllink_ad
